Computer VisionAUC 0.8994
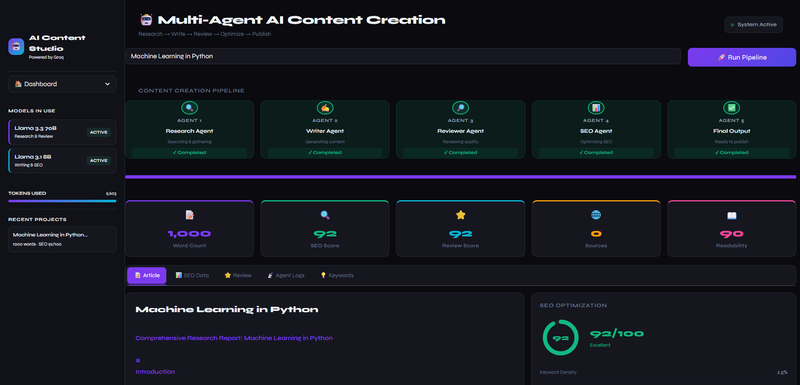
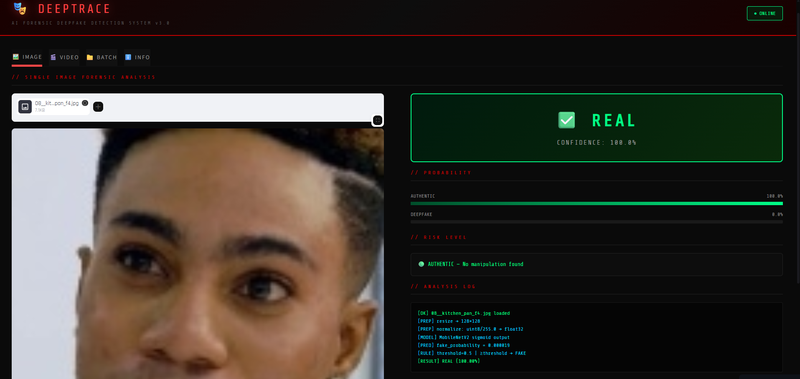
Deepfake Detection System
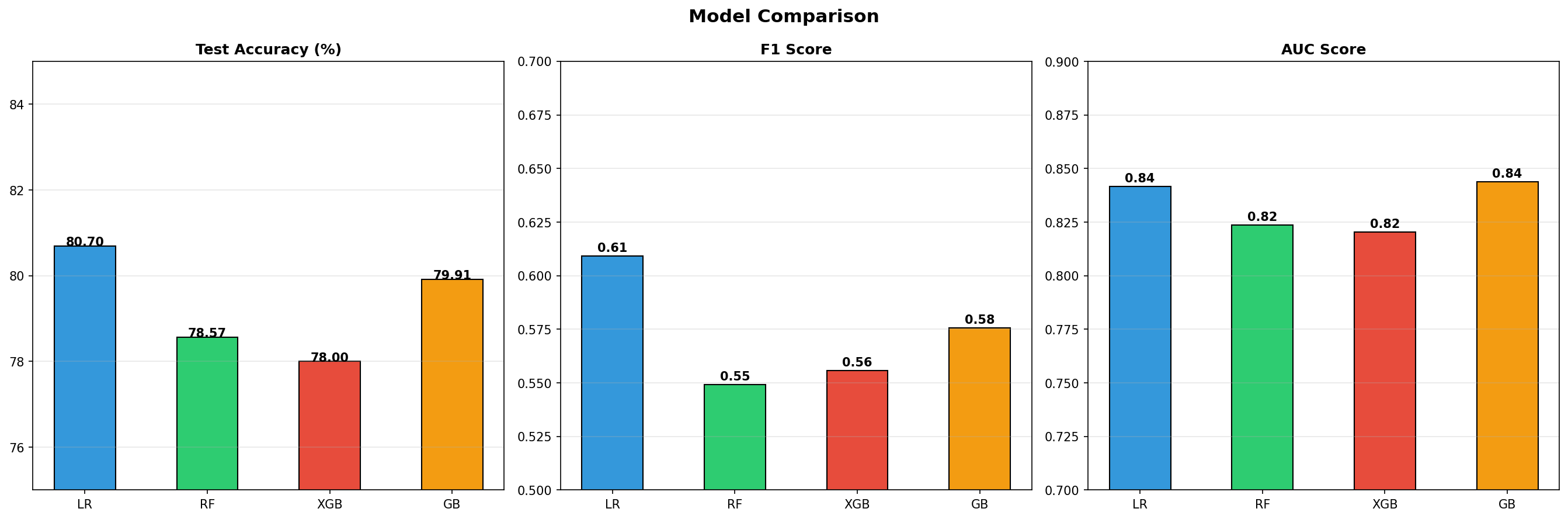
The first version of the model had an AUC of only 0.52 — essentially random guessing. After extensive debugging, the root cause was found: the class labels were reversed during training (fake=0 when it should be fake=1). This one mistake made the model predict the opposite of what was correct.
01Extracted faces from 400 videos (200 real, 200 fake) using OpenCV Haar cascade — creating 3,200 face crops
02Split dataset 70% training, 15% validation, 15% testing with explicit class ordering fixed
03Phase 1: Froze MobileNetV2 base, trained classification head only — AUC jumped to 0.8634
+3 more steps...Key Outcome
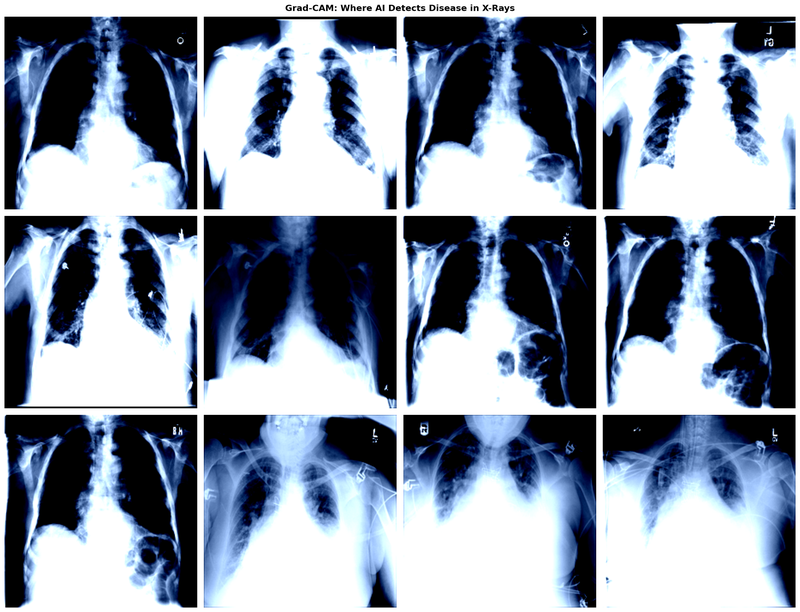
Final validation AUC of 0.8994 — production-ready accuracy. Works on images, video files, and batch processing. The Grad-CAM visualization shows clients exactly where the manipulation happened, making the AI explainable and trustworthy.
PythonTensorFlowMobileNetV2