⚠ The Challenge
Standard chatbots hallucinate answers about specific documents. Businesses need AI that answers accurately from private documents — not from general training data.
💡 The Approach
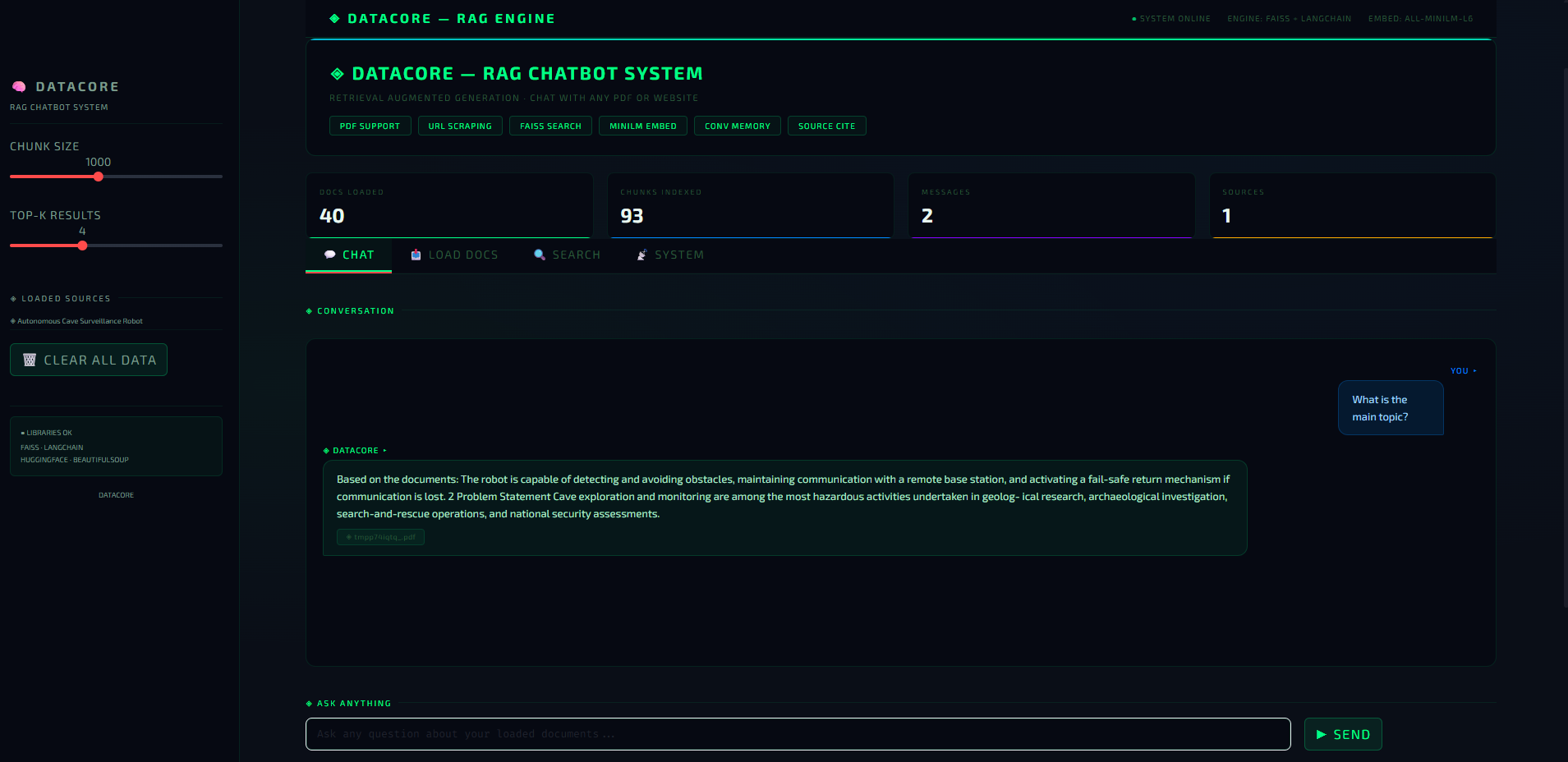
Complete RAG pipeline using LangChain. Documents are split into chunks, converted to vector embeddings, stored in FAISS for semantic search, and retrieved as context for the language model answer.
🔄 Step-by-Step Process
Implemented PDF and URL ingestion — any document or website becomes a knowledge base instantly
Used LangChain text splitter: 500-character segments with 50-character overlap
Generated embeddings using HuggingFace sentence-transformers (all-MiniLM-L6-v2 — free, fast)
Stored embeddings in FAISS vector database for sub-millisecond semantic similarity search
Integrated conversation memory — chatbot remembers previous questions in the same session
Built terminal-themed Streamlit dashboard showing chunk retrieval transparency
✓ Final Result
Accurately answers questions from any PDF or website within seconds. Multi-turn conversation support. Dashboard shows which document chunks were retrieved, making the system fully transparent.
📚 Key Lesson
The quality of text chunking dramatically affects answer quality. Too large = retrieves irrelevant context. Too small = loses meaning. 500 characters with overlap is the sweet spot for most documents.